Pudu Robotics Unveils PuduFM 1.0 and PuduAgent: Defining the Next Era of Humanoid and Embodied AI Systems
SHENZHEN, China, June 05, 2026 (GLOBE NEWSWIRE) -- Over the past few years, the robotics industry has chased one trend after another: humanoids, quadrupeds, robotic arms, and large physical foundation models. But beneath the churn lies a single, decisive question: how does a robot go from an impressive demo to scalable commercial value that keeps getting better over time?
This is not really a story about technology. It is about a company with the largest commercial robot fleet in the world turning a decade of real-world data, hard-won understanding of operating environments, and systems engineering into an advantage that rivals will struggle to copy in the decade to come.
PuduFM 1.0 and PuduAgent are Pudu Robotics' answer to that question. Fresh off a new funding round that has lifted its valuation into the tens of billions, the company has launched two foundational technologies for embodied intelligence: PuduFM 1.0, a robot foundation model, and PuduAgent, a general-purpose embodied agent platform. PuduFM rebuilds how a machine perceives the world based on the idea of physical intuition; PuduAgent provides the unified software foundation that puts that intelligence to work in the physical world. If PuduFM is the brain—one with physical intuition—then PuduAgent is the body that carries that brain and directs what it can do. Together, they bring to life the strategy Pudu Robotics has been building toward for years: One Brain, Multiple Embodiments.
Why Pudu Robotics Set Out to Build a Unified "Brain" for Robots?
In today's embodied intelligence competition, the focus has shifted from "innovation in form" to "breakthroughs at the core."
The reality for the vast majority of robots today is this: Robots can see an obstacle, but they cannot understand what "tilting" means; robots can plan a path, but they cannot anticipate what will happen the next second. What humans regard as common sense is, for a robot, a mountain that is hard to climb.
Pudu Robotics ran into that barrier early. In 2017, its first-generation delivery robot, PuduBot, carried two plates of food through a narrow aisle crowded with diners. The press of people at peak hours, grease on the floor, a child suddenly breaking into a run—none of this looks anything like the clean samples in a standard dataset. It is the messy reality that plays out every day. That experience taught Pudu Robotics that the real world is far more complicated than any lab assumes, and the ability to cope with it—earned in the field rather than the lab—became part of the company's core engineering DNA.
By 2024, Pudu Robotics had become the first in the industry to build a full-category, multi-form product matrix spanning delivery, cleaning, industrial, and general-purpose embodied AI. But the richer the product lineup, the sharper one structural problem became: if every product required its own separately trained brain, R&D resources would be diluted, and data across product lines could not be shared, falling into the trap of "one machine, one model."

This trap is, in fact, a microcosm of the entire industry. Behind it lie three compounding dilemmas:
First, goal drift in ultra-long-horizon tasks. In real commercial delivery, a robot's job is rarely a quick, self-contained action measured in minutes. It is a chain of work that runs for an hour or more, woven together from multi-stage decisions, a changing environment, and interaction with people. To take an order to a hotel room, a delivery robot has to ride elevators, give way to pedestrians, and find the right door—and small errors at each step add up until the task drifts away from what it was meant to do. Pudu Robotics' own deployment data shows that on continuous tasks longer than 30 minutes, traditional systems can fail as often as 40% of the time, and that figure climbs sharply the longer the task runs. The underlying problem is the absence of long-term memory and any way to steer back on course.
Second, endlessly doing the same thing. Although the three core capabilities—navigation, manipulation, and interaction—have each been modularized, they have long lacked unified abstract definitions and orchestration interfaces. Every new project, every change of scenario, requires extensive custom development to connect and adapt them. A seemingly simple transfer—say, from restaurant food delivery to hotel delivery—still demands deep adjustments to the underlying algorithms, and experience transfers almost not at all between robots of different configurations. Take industrial AMRs: with traditional approaches, completing the full process of on-site survey, mapping, and commissioning takes at least several months.
Third, a collective blind spot around physical intuition. Most existing agents are built on language and symbolic systems. They excel at task understanding and information processing, but they severely lack any modeling of physical processes. Take "picking up a tilted cup": a language model can generate a flawless task sequence, but actually carrying it out involves multiple physical constraints—grasp position, force control, posture adjustment, and anticipating contact stability. A robot can see an object, yet cannot understand physical cause and effect; it can move its joints, yet cannot accurately compute the consequences of contact.
These three dilemmas all point to a single root cause: the robotics industry lacks a unified cognitive system that can integrate perception, predict physics, maintain goal consistency across the dimension of time, and be shared across forms. This is exactly why Pudu Robotics resolved to tear everything down and start over.
How "One Brain, Multiple Embodiments" Governs Robots?
Pudu Robotics' response to those structural problems is a strategy it calls One Brain, Multiple Embodiments: robots of different forms (specialized, semi-humanoid, and humanoid) and different categories (delivery, cleaning, industrial, and general-purpose embodied intelligence) all share one unified, end-to-end model and software architecture, so that a single model can address them all.
Because the algorithm is end-to-end and learns from data, the core abilities built up in delivery transfer cleanly to new areas such as cleaning and industrial work. A modest amount of targeted training is enough to bring a new product to market quickly and keep the experience consistent across the lineup.
This frees the product range from the limits of any one vertical. From BellaBot Pro for delivery and CC1 for cleaning, to the T-series industrial AMRs, D5 robot dog, D9 humanoid robot, and the newly launched PUDU D7 industrial semi-humanoid robot, Pudu Robotics’ products may look very different, yet they are increasingly built on the same shared technical foundation.
The arrival of PUDU D7 makes this architecture more tangible. Built for manufacturing and industrial environments, D7 extends the “One Brain, Multiple Embodiments” strategy into complex physical workflows such as material handling, shelf picking, inventory replenishment, intralogistics transport, and precision operations on the factory floor. Powered by PuduFM 1.0, it brings together autonomous mobility, dual-arm manipulation, tactile sensing, 360-degree environmental awareness, and a real-world data loop that allows the system to keep learning from industrial tasks. In this sense, D7 serves as a concrete industrial expression of the same shared intelligence layer, showing how Pudu Robotics is turning foundation-model capability into robots that can understand workflows, adapt to changing conditions, and feed new experience back into the broader product family.
Navigation, manipulation, and interaction are tightly integrated under that one architecture:
-
Navigation: Pudu Robotics progressed from its in-house fusion of laser SLAM and VSLAM algorithms to being the first to introduce autonomous-driving-grade, end-to-end VLA algorithms—completing a paradigm leap from modular to data-driven approaches.
-
Manipulation: From delivery robots equipped with robotic arms, to semi-humanoid robots for hotel and industrial environments, including PUDU D7, to the full-size bipedal humanoid robot D9, the boundaries of manipulation keep expanding.
-
Interaction: From the pioneering touch and facial-expression interaction of the BellaBot series to large-model-based natural language interaction, robots are gaining both "IQ" and "EQ."
The architecture also has a self-reinforcing loop built in. A larger fleet gathers more real-world data; more data makes the model smarter; a smarter model makes better products; better products get deployed more widely still. Knowledge and capability keep moving between robot forms, getting reused and refined along the way.
With more than 130,000 units shipped and a 23% share that puts it first in the global commercial service robot market, Pudu Robotics is the first to take on this architectural shift in embodied intelligence—turning the advantage of scale into a data flywheel that keeps spinning faster. What turns One Brain, Multiple Embodiments from a plan into something real is the pairing at its center: PuduFM 1.0 and PuduAgent.
PuduFM 1.0: Reshaping a Robot's "Physical Common Sense"
So how exactly should this " unified brain" be built?
In 2019, Pudu Robotics ran a delivery pilot at Shenzhen Bao'an Airport. One phenomenon left the engineers puzzled: whenever a robot passed a stretch of highly reflective glass curtain wall, it would suddenly slow down or even stop—it thought it had seen an obstacle, when in fact it was a shadow reflected in the glass. The lead engineer later reflected that if a robot can only process environmental information through traditional "pattern matching," it will never be able to handle every unknown scenario because it lacks the ability to "understand."
This is precisely the core problem PuduFM 1.0 sets out to solve: moving from "matching" to "understanding," from "seeing" to "foreseeing". In essence, this is a paradigm leap for the brain from "perceptual intelligence" to "cognitive and physical intelligence."
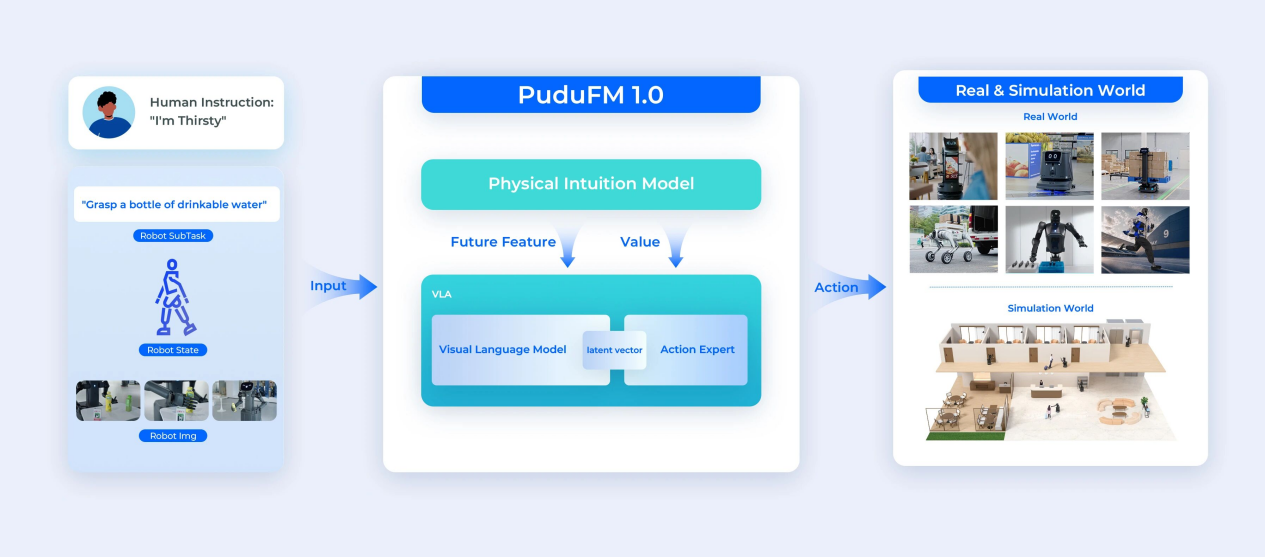
Most industry efforts in this area fall into one of two traps: either they crudely stitch a world model onto a VLA model, leaving an information gap between cognition and execution that is hard to bridge; or they use a single, bloated end-to-end model to cover every feature, whose computational redundancy makes it hard to guarantee the lightweight responsiveness that real-time control requires. PuduFM 1.0's choice is to build an industry-first, lightweight, physical-intuition-driven foundation model, in which two core modules achieve representational synergy at the neural level.
Physical Intuition Model (PIM): Letting Robots "See the Future"
PIM gives a robot foresight. Built on a Causal-Attention Transformer, with slot attention and graph neural network representation, it locks onto the objects that matter in a scene and explicitly models how they interact with one another—the table holding up a cup, the friction between a gripper and what it holds, the way a center of gravity shifts when something deforms.
This is not guesswork over raw pixels; it is the dynamics of the world learned in a latent space. Once a model can take the current state and a planned action and predict, accurately, how the world will look a second later, it can begin to steer the action itself. Handle an object it has never seen, and as long as it understands physics, it can anticipate what interacting with it will do, which is the real key to clearing the generalization hurdle.
So when a running child knocks into a robot and its coffee cup starts to tip, a robot with PIM does not wait until it "sees the cup fall" to react. It reads the risk the instant the cup begins to tilt, and adjusts its posture to steady the tray.

It is worth emphasizing that PIM firmly rejects directly copying the pixel-level future prediction of world models, opting instead for sparse state prediction—achieving three technical breakthroughs:
- Computational efficiency: it avoids redundant pixel-by-pixel computation, supporting higher-frequency real-time inference.
- Control-oriented alignment: it predicts state representations rather than visual pixels, avoiding the problem of "seeing clearly but controlling poorly."
-
Cognitive essence extraction: within the latent space, it strips away surface-level distractions such as visual texture to precisely capture the essence of physical dynamics.
PIM is more than a forecaster; it is also a "judge". The advantage estimates it produces guide the VLA in real time toward the best action, and the moment it spots a risk of collision or instability, it steps in to revise the plan.
Vision-Language-Action Model (VLA): Aligning Three Modalities in a Unified Space
If PIM solves the problem of "physical cognition," VLA tackles the problem of "modal alignment." Mainstream VLA architectures have a structural flaw: language, vision, and action are processed in separate feature spaces, causing "modal misalignment" when the robot reasons.
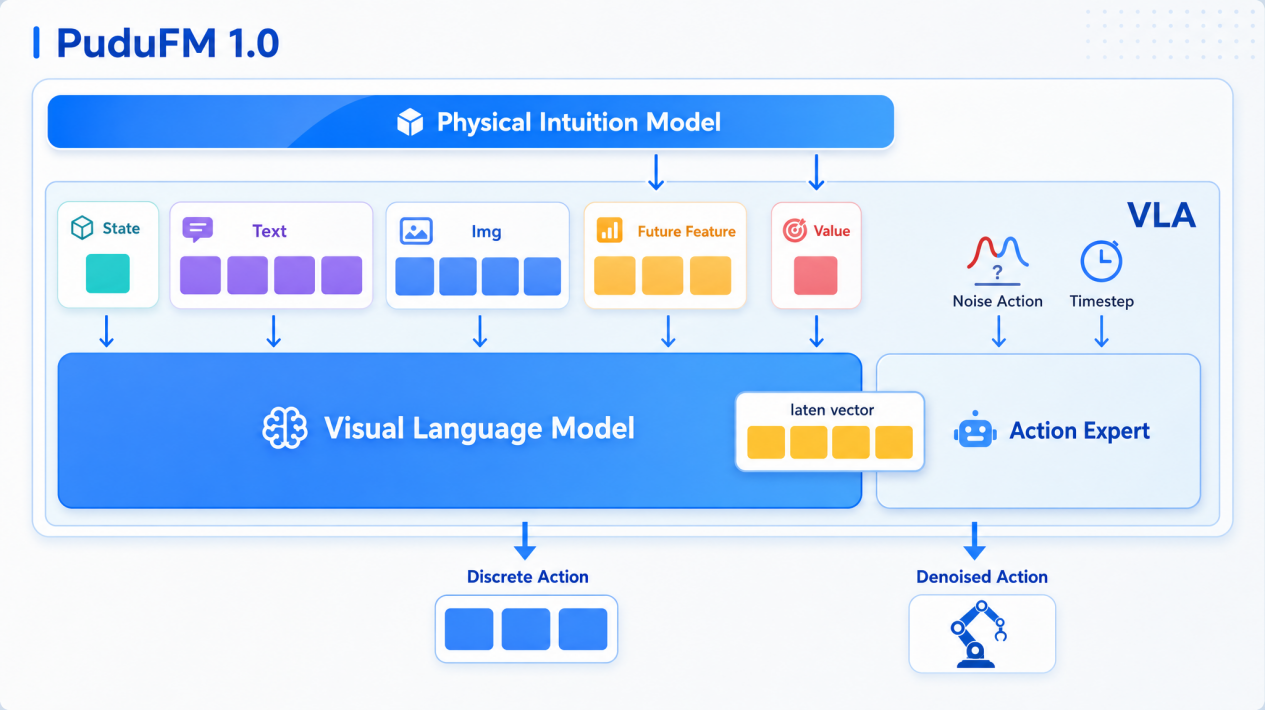
The VLA module in PuduFM 1.0 is the first to achieve deep alignment of all three modalities within a single, unified feature space. Its information flow unfolds across three stages:
- Stage one: physical-intuition guidance. PIM deeply injects physical priors into the VLA decision flow, providing underlying physical-plausibility constraints for action generation.
- Stage two: hierarchical language-vision encoding. Low-level features capture texture and geometric detail, high-level features extract task semantics and intent, and cross-attention deeply fuses PIM's output with the visual and language features.
-
Stage three: progressive action generation. High-level semantics first establish the action's intent, low-level vision then refines the end-effector trajectory, and physical intuition continuously supervises feasibility. For example:
"Grasp the cup" → "Close around the middle" → "The gripping force must be harder than the slip threshold."
With language setting direction, vision sharpening the detail, and physics holding the line, the resulting action is no longer a crude stitch between modalities but a coherent decision that emerges in one shared space. Just as important, it dissolves the old divide between navigation and manipulation: planning a path down a long corridor and exerting the right force on an oddly shaped parcel now run on the same physics, so a Pudu Robotics robot connects "where to go" and "what to do" without a seam.
Because PIM and VLA generalize across different bodies, a robot's embodiment is no longer the ceiling on what the model can do. It is simply another vessel for the same brain. The interaction data that every robot generates in the field flows back into one architecture and feeds the loop, which is what makes One Brain, Multiple Embodiments work at scale.
PuduAgent: Building a General-Purpose Agent Platform for the Physical World
PuduFM 1.0 answers the cognitive question of "how a robot understands the world." PuduAgent answers the systems-engineering question of "how that understanding can be released at scale in real commercial settings."
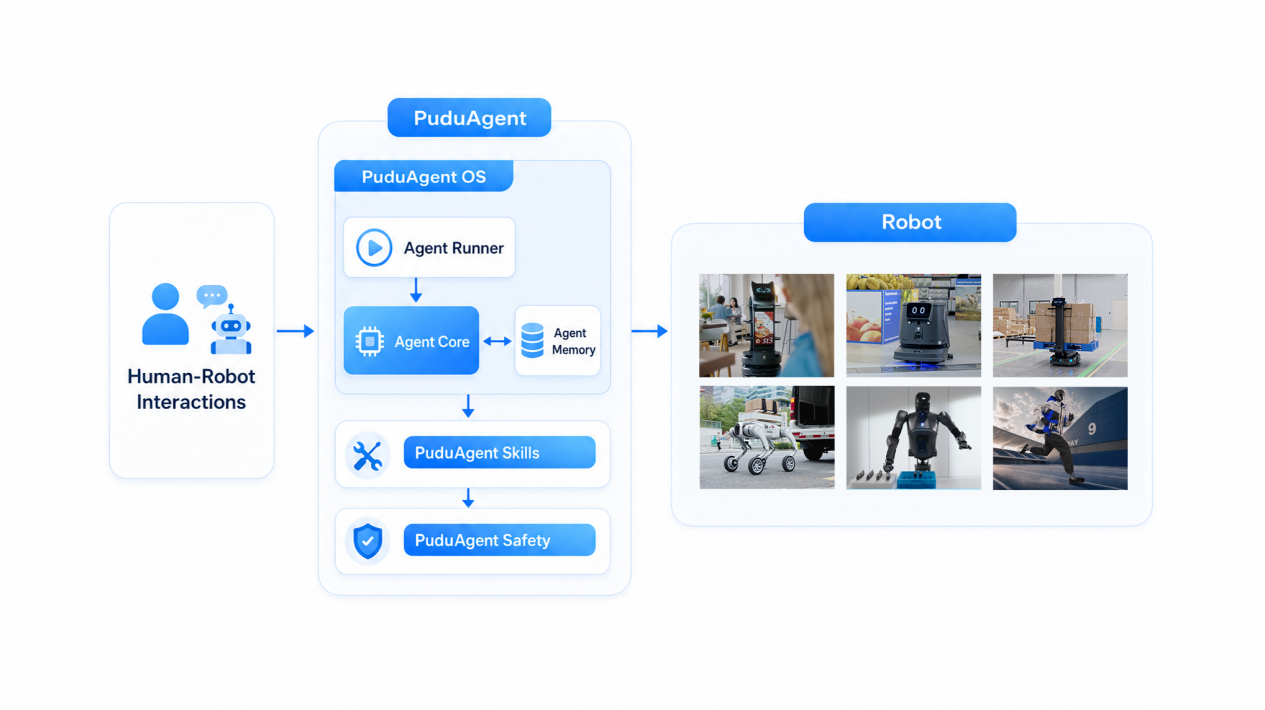
Looking back at the explosion of the mobile internet, the critical turning point was not improved hardware performance, but iOS and Android abstracting complex hardware capabilities into standard APIs, freeing developers to focus on application-layer innovation. Pudu Robotics' view is that for robots to truly be deployed at scale, there must be a unified physical-agent system that lets developers build capabilities as flexibly as by assembling standard modules, rather than reinventing the wheel each time. As a general-purpose embodied agent platform built on top of the PuduFM and designed for developers worldwide, PuduAgent comprises a three-layer architecture: a system layer, a capability layer, and a safety layer.
System Layer: Giving Robots a Cognitive Foundation That "Never Forgets"
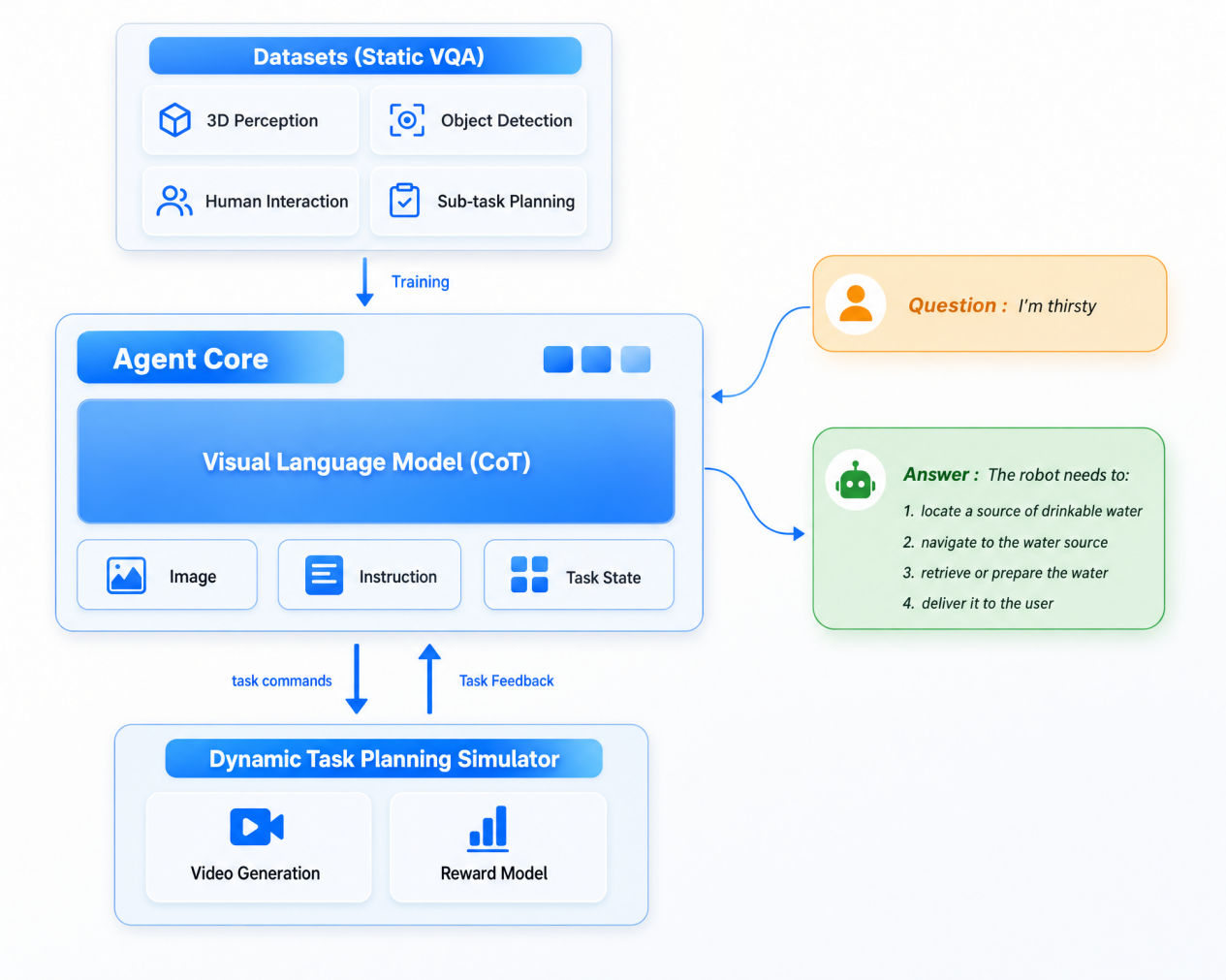
1. Agent Core
Agent Core, the system layer's core capability, lets a robot think like a human shift supervisor. Take hotel delivery: it first performs a macro-level strategic breakdown. For example, it decomposes "deliver a latte to a guest on floor 32" into:
"Go to the lobby bar to collect the order → call the elevator → arrive at floor 32 → identify the room number → hand the order to the guest."
Once this flow is set, it refines it into micro-level tactical execution, such as:
- "Go around the CC1 that is cleaning the corridor."
- "Wait for the elevator doors to open and confirm it is empty before entering."
When a passage is temporarily blocked, it does not rigidly throw an error; instead, it immediately restructures the subsequent steps, reroutes through an alternative path, and recalculates timing.
2. Agent Memory
Agent Memory turns the robot into a "veteran employee" that never forgets. It introduces a three-tier memory structure:
- Working memory maintains the key checkpoints.
- Episodic memory stores the spots where an error occurred in the same scenario previously, so the robot automatically reacts correctly the next time around.
- A memory-compression-and-abstraction system encodes exceptional situations into callable scheduling parameters.
Today, Pudu Robotics' delivery robots are already deployed in many hospitals around the world, where they must deliver medications and specimens to different floors and wards every day, often switching elevators multiple times, crossing connecting corridors, and dodging morning rush-hour crowds along the way. It is precisely this mechanism that keeps a robot clear about its goal throughout continuous tasks lasting up to an hour.
Capability Layer: Reusing Capabilities Like Building Blocks
In a hotel that runs BellaBot, CC1, and PuduBot all at once, these three machines were developed and deployed independently of one another. Under PuduAgent's capability-layer architecture, however, atomic skills such as navigation, obstacle avoidance, path planning, elevator interaction, and voice response are abstracted into standardized modules and held in a capability library that any authorized machine can call. As a result, when a cleaning robot enters a new floor for the first time, it does not need to re-map it—it can directly call the maps and obstacle-avoidance data already accumulated for that floor; and a newly introduced AMR does not need to relearn how to ride the elevator—it directly calls the existing elevator-interaction skill and only adapts the parameters to its own dimensions.
More noteworthy still, the capability layer remains transparent to the underlying model: in known, fixed scenarios, it calls a thoroughly validated end-to-end navigation algorithm, while in unknown or highly dynamic scenarios, it switches to a VLA model with zero-shot generalization. Developers need not concern themselves with which model runs underneath; they only define the task goal, and the system automatically handles skill matching and scheduling.
Safety Layer: The Red Line That Cannot Be Crossed in the Physical World
Before every action is executed, the safety layer makes a feasibility judgment: does this action satisfy physical constraints? It proactively identifies risks such as potential collisions, overloads, and instability, and when it detects an anomaly, it adjusts or aborts the task rather than rigidly continuing. By raising safety constraints from the application layer up to the platform layer, it effectively lowers the cost of trial and error in real-world environments.
From Single-Machine Intelligence to Swarm Coordination and an Open Ecosystem
One of PuduAgent's real strengths is taking coordination among different kinds of robots out of theory and into practice. Through a shared Agent OS scheduler, machines of different forms and different limits become standard, schedulable resources; the system breaks down, assigns, and reassigns work in real time according to the task, the environment, and what each machine can currently do. Sharing Memory, the robots also keep a common picture of the environment and the job's progress, so information never fragments and work is not done twice.
For developers, Pudu Robotics offers a full SDK, a simulation environment, and the SkillHub marketplace.
A third-party developer could, for instance, build a pharmaceutical warehouse in simulation, pull a ready-made "warehouse navigation" skill from SkillHub, add a "temperature and humidity" module, write their own "expiry-date check," and ship the lot as a "pharmacy inspection" app. They need no understand of the math behind SLAM, no LiDAR drivers to debug, not even a physical robot—what works in simulation transfers straight onto Pudu Robotics hardware.
More skills mean broader coverage; more developers mean more skills. Once that flywheel is turning, it becomes an ecosystem advantage that is hard for anyone to copy.
Conclusion
While much of the industry is still arguing over which form of robot will win, Pudu Robotics has quietly changed the question. The point is not which robot rules them all, but how robots of many forms work together, under one brain, to serve people.
It means the robots you meet in hotels, hospitals, factories, and malls will stop being rigid machines that follow a script and push blindly ahead. Like a well-trained colleague, they will read your intent, see trouble coming, fall into step when you need them, and ease out of your way as you pass—delivering a coffee with a little grace, or handling a difficult lift safely on a worksite. Behind that experience sits a clear stack: One Brain, Multiple Embodiments as the framework, PuduFM as the engine, and PuduAgent as the platform that carries it out.
To give the physical world a mind, and embodied intelligence a set of rules to live by. The commercialization of embodied intelligence that Pudu Robotics is leading has only just begun.
About Pudu Robotics
Founded in Shenzhen in 2016, Pudu Robotics is a global leader in commercial service robots, with a product matrix spanning commercial cleaning, service delivery, industrial delivery, and embodied intelligence robots, among other categories. According to a Frost & Sullivan report, Pudu Robotics holds a 23% market share, ranking first in the global commercial service robot market. As of the publication of this article, Pudu Robotics has shipped more than 130,000 robots and achieved large-scale deployment in over 80 countries worldwide.
Media Contacts
Website: https://www.pudurobotics.com/en
Email: pr@pudutech.com
Photos accompanying this announcement are available at
https://www.globenewswire.com/NewsRoom/AttachmentNg/21410d41-041f-4476-85eb-91a29df97933
https://www.globenewswire.com/NewsRoom/AttachmentNg/8d82cf78-4246-4c2e-9f12-2bde3d418971
https://www.globenewswire.com/NewsRoom/AttachmentNg/d757b566-37e7-40f7-9426-14681a78dfd0
https://www.globenewswire.com/NewsRoom/AttachmentNg/12ea2c55-ecb1-48e1-9d81-864cd5ad719f
https://www.globenewswire.com/NewsRoom/AttachmentNg/829f749b-42a0-4d43-a503-cbe5a823ffce
https://www.globenewswire.com/NewsRoom/AttachmentNg/001f9c30-126d-4f29-b5df-34945de28da2

![]()
Pudu Robotics product matrix

Pudu Robotics product matrix
PuduFM 1.0 paradigm shift
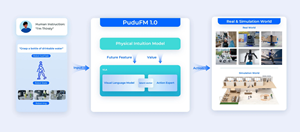
PuduFM 1.0 paradigm shift
Pudu Robotics Unveils PuduFM 1.0 and PuduAgent Defining the Next Era of Humanoid and Embodied AI Systems

Pudu Robotics Unveils PuduFM 1.0 and PuduAgent Defining the Next Era of Humanoid and Embodied AI Systems
VLA model aligning three modalities in unified feature space for robot reasoning
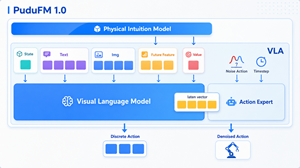
VLA model aligning three modalities in unified feature space for robot reasoning
PuduAgent three-layer architecture
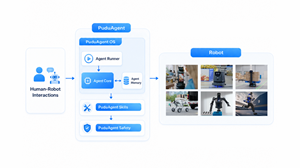
PuduAgent three-layer architecture
Agent Core decomposing hotel delivery task into macro and micro execution steps for service robot
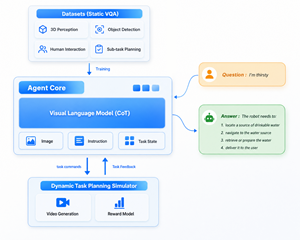
Agent Core decomposing hotel delivery task into macro and micro execution steps for service robot
Legal Disclaimer:
EIN Presswire provides this news content "as is" without warranty of any kind. We do not accept any responsibility or liability for the accuracy, content, images, videos, licenses, completeness, legality, or reliability of the information contained in this article. If you have any complaints or copyright issues related to this article, kindly contact the author above.
